El dicho popular dice que hay tres tipos de mentiras: mentiras pequeñas, mentiras grandes y mentiras estadísticas. Y no es que la estadística sea inútil, muy por el contrario es un conjunto de técnicas y herramientas en la que descansa gran parte de la ciencia y tecnología moderna, y que apropiadamente usada nos permite obtener valiosa información sobre el comportamiento de muchos y diversos fenómenos. Sin embargo como cualquier herramienta sofisticada requiere de personas con conocimiento, experiencia y criterio en su análisis e interpretación. De lo contrario es muy fácil su manipulación para conclusiones erróneas. Esta característica fue recogida en 1954 en el famoso libro de Darrell Huff “cómo mentir con estadísticas” que hoy en día es prácticamente un clásico entre interesados en el tema y que se los recomiendo ampliamente por el lenguaje sencillo y con cierto toque de humor que utiliza.
Una forma de ilustrar este punto es con un ejemplo que relacione estadísticamente cosas ridículas. El ejemplo que tomaremos es la predicción del número de crímenes violentos en Estados Unidos con el número de graduados de doctorados universitarios en diferentes especialidades en ese país. Es un buen ejemplo porque nadie en su sano juicio atribuiría causalidad entre una y otra variable, sin embargo mostraremos como es posible llegar a conclusiones erradas utilizando ciegamente las estadísticas. Tomamos los datos que publican en su página web el FBI y la NSF (National Science Foundation) para los años 2000 al 2010. Utilizando una práctica común, normalizamos los datos dividiendo por el valor del 2000 y multiplicando por 100 de forma que ese año sea la base de comparación inicial base 100 con lo que nos queda la Tabla 1.
Tabla 1 Número crímenes violentes y graduados de doctorado de diferentes áreas en USA. 2000=100
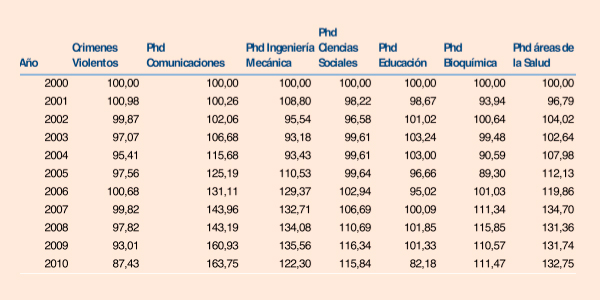
Fuente: NSF y FBI
En la Tabla 2 se presentan las correlaciones entre las diferentes variables de la Tabla 1. Si miramos la primera columna de la Tabla 2 se puede observar una correlación en torno -0,7 entre crímenes violentos y los graduados de doctorados en comunicaciones y ciencias sociales y una de 0,6 con doctorados Educación. Dudo que alguien fuera a proponer aumentar los cupos en doctorados de los primeros y una disminución de los cupos en doctorados en educación como una forma de combate a la delincuencia, sin embargo a menudo nos encontramos con tajantes afirmaciones de causalidad en situaciones que no difieren mucho de esta.
Tabla 2. Matriz de correlaciones
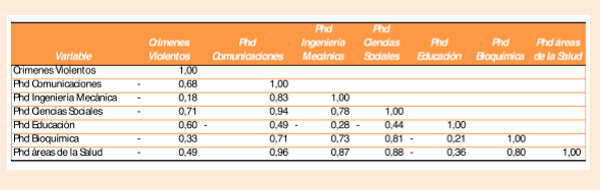
Podemos ir un poco más allá de las correlaciones a una forma más sofisticada de mentira estadística como pueden ser las regresiones con múltiples variables. Al realizar la regresión entre crímenes violentos y 5 variables con número de doctorados en diferentes disciplinas obtenemos los coeficientes de la Tabla 3, prácticamente todos ellos son estadísticamente significativos con una confiabilidad del 95%. Es más la regresión tiene un R-cuadrado bastante alto de 0.992 y un R-cuadrado ajustado de 0.985. El error estándar es de sólo el 0.5% por lo que la confiabilidad teórica de la predicción es de +-1.28% con 99% de confianza. La regresión como un todo tiene un nivel de significancia superior al 99.999%.
Tabla 3 Coeficientes de regresión utilizando el índice de Crímenes Violentos como variable independiente Y
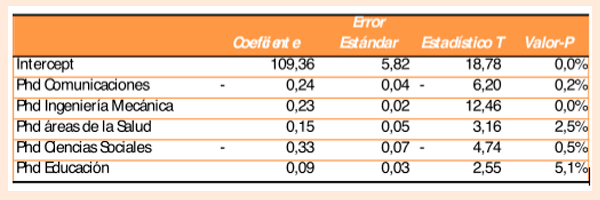
Con esos número pareciera un excelente modelo ¿O no?. Alguien un poco más informado podría plantear que hay un problema de sobreajuste al usar tantas variables predictivas. En un extremo si utilizamos 10 variables independientes el ajuste sería perfecto, el R-cuadrado sería igual a 1 aunque no tendría ningún sentido práctico ni predictivo. Para eliminar este problema hacemos un modelo muy sencillo con una sola variable y dos parámetros consistente en:
Índice Crímenes Violentos = a + b Z
Con, Z = Índice Phd Ingeniería Mecánica – Índice Phd Comunicaciones
Obteniendo los coeficientes de regresión de la Tabla 4 con un R-cuadrado más que respetable de 0.95, un R-cuadrado ajustado de 0.89 y un error estándar de sólo 1,35%, lo que da un error teórico de predicción de +-3.5% con 99% de confianza.
Tabla 4 Coeficientes de regresión 2° modelo

La evidencia estadística parece contundente y la tentación de llegar a concluir que hay que disminuir las vacantes en doctorados en Ingeniería Mecánica y aumentar las de comunicaciones para disminuir los crímenes violentos es grande, pero claramente algo anda mal en esa interpretación ¿Cuál es el problema entonces si los números se ven tan bien?
Los problemas son múltiples, pero mencionaremos los principales. El principal problema es que no hay ninguna teoría detrás. Se eligieron variables por su concordancia con los datos y no porque tengan algún sentido. De hecho esas 5 variables fueron selectivamente escogidas de un conjunto de más de 37 especialidades de doctorado, entonces no es raro encontrar 5 que por simple casualidad se ajustan mejor a los datos de criminalidad. No olvide que la estadística es una excelente forma de testear hipótesis y pero una no muy útil para construir las hipótesis que queremos verificar. Esto nos lleva al segundo problema que en ciencias sociales es muy corriente la correlación entre variables porque el resultado depende de macro variables económicas, demográficas y sociológicas que afectan el comportamiento humano en múltiples dimensiones y por lo tanto suele haber bastante correlación en cosas que no tienen relación de causalidad directa pero si indirecta a través de una macro tendencia subyacente. No hay que olvidar que correlación o ajuste en un modelo no implica causalidad y puede que la relación entre ambas sea a través de otro fenómeno no evidente. El tercer problema es que la muestra es pequeña, de sólo 11 observaciones, lo que exacerba el primer problema. Los modelos estadísticos hacen supuestos importantes sobre la distribución probabilística de las variables observadas, y su cumplimiento estricto es menos relevante cuando el número de observaciones es grande. Lamentablemente la precisión de las estimaciones en general aumenta con la raíz cuadrada del número de observaciones, por lo tanto si quiero obtener el doble de precisión requiero del cuádruple de observaciones. Además el número de observaciones necesarias para mantener la precisión de cada parámetro aumenta en forma exponencial con el número de parámetros a estimar y es por ello la necesidad de utilizar pocos parámetros en la estimación a menos que se cuente con muchísimas observaciones. El contar con un gran número de observaciones también permite estimar el modelo con una parte de los datos y probar su poder predictivo con la otra parte que no se utilizó en la estimación. Por ejemplo dudo que los modelos aquí planteados pudieran predecir correctamente lo que ocurrió de 1990 a 1999 y el error real de estimación en este período seguro es mucho mayor al evaluarlo en esa muestra que la simple predicción teórica. En el segundo modelo estimado en la Tabla 4 parece un modelo simple, en que sólo se estiman dos parámetros a y b, pero hay varios más que están ocultos: uno es la definición de Z = Índice Phd Ingeniería Mecánica – Índice Phd Comunicaciones que fue escogida de esa forma mirando los coeficientes de la Tabla 3 y no porque tenga alguna lógica a priori. Los otros son la selección de esas dos variables de entre una lista de 37, esta selección es una forma de parametrizar ya que si hizo en base a los mismos datos y no a priori.
Como conclusión, fíjese siempre en la teoría y otra evidencia detrás de la estadística, la cantidad de observaciones y el número de parámetros directos e indirectos que utiliza un modelo, de forma de poder realizar una evaluación más crítica del análisis que se le presenta. De otra forma terminará proponiendo políticas públicas que eliminen los doctorados en Ingeniería mecánica como una forma de disminuir la delincuencia.





 VER MÁS
VER MÁS MARKET DATA
MARKET DATA (Twitter)
(Twitter) Instagram
Instagram Facebook
Facebook LinkedIn
LinkedIn YouTube
YouTube TikTok
TikTok

































































